neo4j
NEO4J
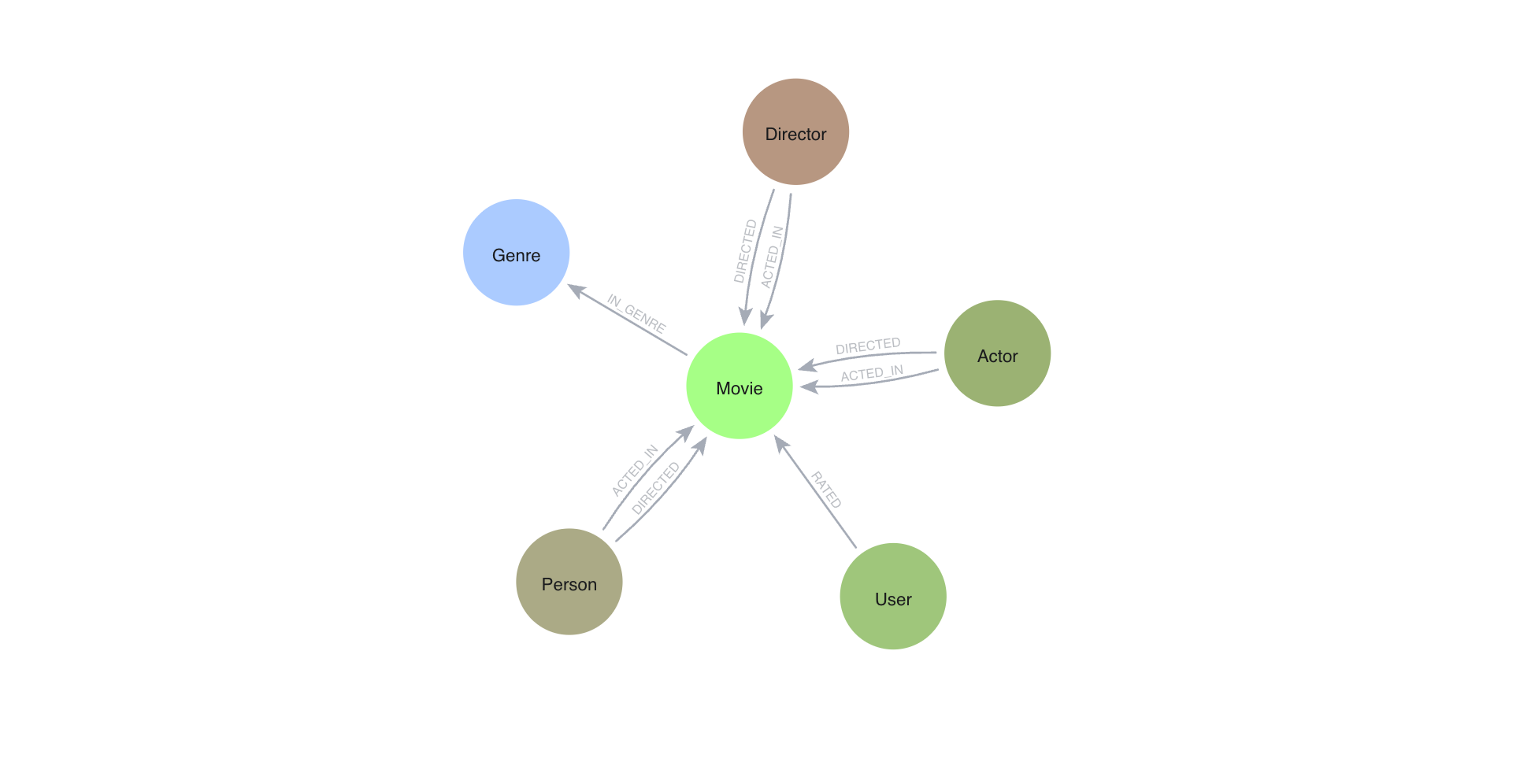
statistics
# remove all relations
MATCH ()-[r]->() DELETE r;
# remove all data
MATCH (n) DETACH DELETE n;
// 1. 删除所有索引
CALL apoc.schema.assert({}, {}, true) YIELD label, key
RETURN *;
// 2. 删除所有约束
CALL apoc.schema.constraints() YIELD name
CALL apoc.schema.dropConstraint(name)
RETURN *;
// 3. 删除所有节点和关系
MATCH (n)
DETACH DELETE n;
// large data center, batch delete(每次删除10000个节点)
MATCH (n)
WITH n LIMIT 10000
DETACH DELETE n
RETURN count(n) as deleted;
// 重复执行直到返回 0
// Match all nodes and remove all their properties
MATCH (n)
SET n = {};
// Match all relationships and remove all their properties
MATCH ()-[r]->()
SET r = {};
// Batch-clear node properties (10k nodes at a time)
MATCH (n)
WITH n LIMIT 10000
SET n = {}
RETURN count(n) as updated_nodes;
// Repeat until the return value is 0
// 各标签节点数量(推荐)
CALL db.labels() YIELD label
MATCH (n) WHERE label IN labels(n)
RETURN label, count(n) AS count
ORDER BY count DESC;
// 或使用 APOC(如已安装)
CALL apoc.meta.nodeTypeCounts() YIELD label, count
RETURN label, count ORDER BY count DESC;
// 各关系类型数量
CALL db.relationshipTypes() YIELD relationshipType
MATCH ()-[r]->() WHERE type(r) = relationshipType
RETURN relationshipType, count(r) AS count
ORDER BY count DESC;
// 或使用 APOC
CALL apoc.meta.relTypeCounts() YIELD start, type, end, count
RETURN type, count ORDER BY count DESC;
// 查看某个节点有拥有的关系,替换成你的节点匹配条件
MATCH (n:Apartment {apartment_id: "69846d8973bbdebb6e8b0609"})-[r]-()
RETURN DISTINCT type(r) AS relationship_type
ORDER BY relationship_type
二、Schema 结构探索
查看所有标签及其属性键
CALL db.schema.nodeTypeProperties()
YIELD nodeType, propertyName, propertyTypes, mandatory
RETURN nodeType, collect({
prop: propertyName,
type: propertyTypes,
required: mandatory
}) AS properties
ORDER BY nodeType;
列出每个节点标签拥有哪些属性、属性类型、是否必填,相当于查"表结构"。
查看所有关系及其属性键
CALL db.schema.relTypeProperties()
YIELD relType, propertyName, propertyTypes
RETURN relType, collect({
prop: propertyName,
type: propertyTypes
}) AS properties
ORDER BY relType;
查关系上挂了哪些属性,便于理解边的"权重"或"元数据"。
可视化 Schema 全图(Neo4j Browser 专用)
CALL db.schema.visualization();
在 Neo4j Browser 中调用,直接渲染节点类型 → 关系类型的宏观拓扑图,一眼看清全局。
查看所有索引
SHOW INDEXES
YIELD name, type, labelsOrTypes, properties, state
RETURN name, type, labelsOrTypes, properties, state
ORDER BY type, name;
了解哪些属性已建索引,判断查询性能瓶颈的基础。
查看所有约束
SHOW CONSTRAINTS
YIELD name, type, labelsOrTypes, properties
RETURN name, type, labelsOrTypes, properties;
唯一约束、存在性约束,帮你理解数据完整性规则。
三、节点属性分布
某标签节点的属性覆盖率
MATCH (n:Person)
WITH count(n) AS total
MATCH (n:Person)
RETURN
total,
count(n.name) AS has_name,
count(n.age) AS has_age,
count(n.email) AS has_email,
round(100.0 * count(n.name) / total, 1) AS name_pct,
round(100.0 * count(n.age) / total, 1) AS age_pct,
round(100.0 * count(n.email) / total, 1) AS email_pct;
将
Person换成你的标签名,快速发现哪些属性是稀疏的(大量 null)。
节点拥有的标签组合分布
MATCH (n)
WITH labels(n) AS lbls, count(*) AS cnt
RETURN lbls, cnt
ORDER BY cnt DESC
LIMIT 20;
发现多标签节点组合(如同时是 Person + Employee),理解多继承关系。
四、拓扑连接分析
节点度数分布(Top 出入度)
MATCH (n)
WITH n,
size((n)-[*1..1]->()) AS out_deg,
size((n)<-[*1..1]-()) AS in_deg
RETURN
labels(n) AS label,
n.name AS name,
in_deg, out_deg,
in_deg + out_deg AS total_deg
ORDER BY total_deg DESC
LIMIT 20;
找出图中的"超级节点"(Hub),高度数节点通常是数据质量或性能热点。
关系类型的起点 → 终点标签组合
MATCH (a)-[r]->(b)
RETURN
labels(a) AS from_labels,
type(r) AS rel_type,
labels(b) AS to_labels,
count(r) AS count
ORDER BY count DESC
LIMIT 30;
精确了解每种关系连接的是哪两类节点,比 schema 图更具体。
孤立节点(无任何关系)
MATCH (n)
WHERE NOT (n)--()
RETURN labels(n) AS label, count(n) AS isolated_count
ORDER BY isolated_count DESC;
孤立节点往往意味着数据导入问题或垃圾数据。
五、路径与关联深度
两节点间最短路径
MATCH p = shortestPath(
(a:Person {name: "Alice"})-[*]-(b:Person {name: "Bob"})
)
RETURN p, length(p) AS hops;
替换节点名,查看两个实体在图中相距几跳,直观感受图的稀疏/紧密程度。
N 跳邻居规模(感知图密度)
MATCH (n {name: "Alice"})
RETURN
size([(n)-[*1]->(x) | x]) AS neighbors_1hop,
size([(n)-[*2]->(x) | x]) AS neighbors_2hop,
size([(n)-[*3]->(x) | x]) AS neighbors_3hop;
随着跳数增加邻居是否爆炸式增长,是判断图是否是小世界网络的简单方式。
六、性能与元数据
查询执行计划(不实际执行)
EXPLAIN
MATCH (n:Person)-[:KNOWS]->(m:Person)
WHERE n.age > 30
RETURN n.name, m.name;
加
EXPLAIN前缀,查看查询是否走了索引、全表扫描代价多大,不实际执行。调试慢查询时养成先 EXPLAIN 的习惯。
数据库整体统计(需 APOC 插件)
CALL apoc.meta.stats()
YIELD nodeCount, relCount, labels, relTypesCount
RETURN nodeCount, relCount, labels, relTypesCount;
返回缓存的统计数据,比
count(*)快得多。需安装 APOC 插件。
随机采样一批节点(快速摸底)
MATCH (n)
WITH n, rand() AS r
ORDER BY r
LIMIT 10
RETURN labels(n), keys(n), n;
随机抽 10 个节点,看看实际数据长什么样,快速了解属性值格式。
速查索引
| 目的 | 关键命令 |
|---|---|
| 节点数量按标签 | db.labels() + MATCH count |
| 关系数量按类型 | db.relationshipTypes() + MATCH count |
| 节点属性结构 | db.schema.nodeTypeProperties() |
| 关系属性结构 | db.schema.relTypeProperties() |
| 可视化全图 | db.schema.visualization() |
| 索引列表 | SHOW INDEXES |
| 约束列表 | SHOW CONSTRAINTS |
| 属性覆盖率 | count(n.prop) / count(n) |
| 超级节点 | size((n)-->()) 排序 |
| 关系连接对 | labels(a) + type(r) + labels(b) |
| 孤立节点 | WHERE NOT (n)--() |
| 最短路径 | shortestPath() |
| N 跳邻居 | `size([(n)-[*N]->(x) \ |
| 执行计划 | EXPLAIN 前缀 |
| 全库统计 | apoc.meta.stats() |
| 随机采样 | rand() + LIMIT |
Backup and restore
| restore schema first, then data
# export cypher
CALL apoc.export.cypher.all("all.cypher", {
useOptimizations: {type: "UNWIND_BATCH", unwindBatchSize: 1000}
});
# verify
ls /data/neo4j/import/
all.cypher
# restore by cypher
:play all.cypher
# or
cypher-shell -u neo4j -p xxx < all.cypher
# export json
CALL apoc.export.json.all("20260326_dev.json", {});
# this will only export Nodes/Relationships/nodes-relationships-attributes
# this will NOT export Indexes/Constraints/Internal neo4j IDs
# export csv
CALL apoc.export.csv.all("20260326_dev.csv", {});
# import by json
CALL apoc.import.json("20260326_dev.json", {
batchSize: 1000,
parallel: true
});
# use following if OOM
CALL apoc.import.json("20260326_dev.json", {
batchSize: 500,
parallel: false
});
# only export schema: constraints, indexes, labels / rel types
CALL apoc.export.cypher.schema("schema.cypher", {});
# restore indexes, constraints
cypher-shell -u neo4j -p xxx < schema.cypher
# show constraints; CREATE/CONSTRAINT/INDEX
CALL apoc.export.cypher.all("full.cypher", {
format: "plain"
});
# use following for small data to export
CALL apoc.export.cypher.all("full.cypher", {});
# restore
cypher-shell -u neo4j -p xxx < full.cypher
还原顺序(重要)
- 启动新库
- 先执行所有 CREATE CONSTRAINT ← 约束会自动创建隐含索引
- 再执行额外的 CREATE INDEX
- 等待索引 ONLINE 后再导入数据
- 执行 apoc.import.json 导入数据
等待索引就绪:
SHOW INDEXES YIELD name, state
WHERE state <> "ONLINE"
RETURN name, state;
Database manage
# create db
CREATE DATABASE rag_test;
# view dbs
SHOW DATABASES;
# remove db
DROP DATABASE rag_test;
# remove if in use
DROP DATABASE rag_test IF EXISTS;
# or
DROP DATABASE rag_test WAIT;
# alter db
:use rent_db;
# or use bash
cypher-shell -d rent_db
# select dabase
:use neo4j
# create data
MERGE (:Movie {title: 'Apollo 13', tmdbId: 568, released: '1995-06-30', imdbRating: 7.6, genres: ['Drama', 'Adventure', 'IMAX']})
MERGE (:Person {name: 'Tom Hanks', tmdbId: 31, born: '1956-07-09'})
MERGE (:Person {name: 'Meg Ryan', tmdbId: 5344, born: '1961-11-19'})
MERGE (:Person {name: 'Danny DeVito', tmdbId: 518, born: '1944-11-17'})
MERGE (:Person {name: 'Jack Nicholson', tmdbId: 514, born: '1937-04-22'})
MERGE (:Movie {title: 'Sleepless in Seattle', tmdbId: 858, released: '1993-06-25', imdbRating: 6.8, genres: ['Comedy', 'Drama', 'Romance']})
MERGE (:Movie {title: 'Hoffa', tmdbId: 10410, released: '1992-12-25', imdbRating: 6.6, genres: ['Crime', 'Drama']})
# verify created
MATCH (n:Movie) RETURN n LIMIT 25
MATCH (n:Person) RETURN n LIMIT 25
# create other data
MERGE (s:User {userId: 534})
SET s.name = "Sandy Jones"
MERGE (c:User {userId: 105})
SET c.name = "Clinton Spencer"
# query
MATCH (u:User)
RETURN u.userId, u.name
# create the relationships between nodes
MATCH (apollo:Movie {title: 'Apollo 13'})
MATCH (tom:Person {name: 'Tom Hanks'})
MATCH (meg:Person {name: 'Meg Ryan'})
MATCH (danny:Person {name: 'Danny DeVito'})
MATCH (sleep:Movie {title: 'Sleepless in Seattle'})
MATCH (hoffa:Movie {title: 'Hoffa'})
MATCH (jack:Person {name: 'Jack Nicholson'})
MERGE (tom)-[:ACTED_IN {role: 'Jim Lovell'}]->(apollo)
MERGE (tom)-[:ACTED_IN {role: 'Sam Baldwin'}]->(sleep)
MERGE (meg)-[:ACTED_IN {role: 'Annie Reed'}]->(sleep)
MERGE (danny)-[:ACTED_IN {role: 'Bobby Ciaro'}]->(hoffa)
MERGE (danny)-[:DIRECTED]->(hoffa)
MERGE (jack)-[:ACTED_IN {role: 'Jimmy Hoffa'}]->(hoffa)
# verify relationship
MATCH (p:Person)-[a:ACTED_IN]->(m:Movie)
RETURN p, a, m
# create more relationship
MATCH (sandy:User {name: 'Sandy Jones'})
MATCH (clinton:User {name: 'Clinton Spencer'})
MATCH (apollo:Movie {title: 'Apollo 13'})
MATCH (sleep:Movie {title: 'Sleepless in Seattle'})
MATCH (hoffa:Movie {title: 'Hoffa'})
MERGE (sandy)-[:RATED {rating:5}]->(apollo)
MERGE (sandy)-[:RATED {rating:4}]->(sleep)
MERGE (clinton)-[:RATED {rating:3}]->(apollo)
MERGE (clinton)-[:RATED {rating:3}]->(sleep)
MERGE (clinton)-[:RATED {rating:3}]->(hoffa)
# what people acted in a movie?
MATCH (p:Person)-[:ACTED_IN]-(m:Movie)
WHERE m.title = 'Sleepless in Seattle'
RETURN p.name AS Actor
# What person directed a movie?
MATCH (p:Person)-[:DIRECTED]-(m:Movie)
WHERE m.title = 'Hoffa'
RETURN p.name AS Director
# What movies did a person act in?
MATCH (p:Person)-[:ACTED_IN]-(m:Movie)
WHERE p.name = 'Tom Hanks'
RETURN m.title AS Movie
# How many users rated a movie?
MATCH (u:User)-[:RATED]-(m:Movie)
WHERE m.title = 'Apollo 13'
RETURN count(*) AS `Number of reviewers`
# Who was the youngest person to act in a movie?
MATCH (p:Person)-[:ACTED_IN]-(m:Movie)
WHERE m.title = 'Hoffa'
RETURN p.name AS Actor, p.born as `Year Born` ORDER BY p.born DESC LIMIT 1
# What role did a person play in a movie?
MATCH (p:Person)-[r:ACTED_IN]-(m:Movie)
WHERE m.title = 'Sleepless in Seattle' AND
p.name = 'Meg Ryan'
RETURN r.role AS Role
# What is the highest rated movie in a particular year according to imDB?
MATCH (m:Movie)
WHERE m.released STARTS WITH '1995'
RETURN m.title as Movie, m.imdbRating as Rating ORDER BY m.imdbRating DESC LIMIT 1
# add data
MERGE (casino:Movie {title: 'Casino', tmdbId: 524, released: '1995-11-22', imdbRating: 8.2, genres: ['Drama','Crime']})
MERGE (martin:Person {name: 'Martin Scorsese', tmdbId: 1032})
MERGE (martin)-[:DIRECTED]->(casino)
# What drama movies did an actor act in?
MATCH (p:Person)-[:ACTED_IN]-(m:Movie)
WHERE p.name = 'Tom Hanks' AND
'Drama' IN m.genres
RETURN m.title AS Movie
# What users gave a movie a rating of 5?
MATCH (u:User)-[r:RATED]-(m:Movie)
WHERE m.title = 'Apollo 13' AND
r.rating = 5
RETURN u.name as Reviewer
Refactoring
# view performance of a query
PROFILE MATCH (p:Person)-[:ACTED_IN]-()
WHERE p.born < '1950'
RETURN p.name
# refactor a graph (Add new Label)
MATCH (p:Person)
WHERE exists ((p)-[:ACTED_IN]-())
SET p:Actor
# check the results
MATCH (p:Actor)
RETURN p
# profiliing queries
MATCH (p:Actor)-[:ACTED_IN]-(m:Movie)
WHERE m.title = 'Sleepless in Seattle'
RETURN p.name AS Actor
# add other label
MATCH (p:Person)
WHERE exists ((p)-[:DIRECTED]->())
SET p:Director
# turn the property values into nodes
MATCH (m:Movie)
UNWIND m.languages AS language
MERGE (l:Language {name:language})
MERGE (m)-[:IN_LANGUAGE]->(l)
SET m.languages = null
# verify
MATCH (m:Movie)-[:IN_LANGUAGE]-(l:Language)
WHERE l.name = 'Italian'
RETURN m.title
# continue refactor Genre
MATCH (m:Movie)
UNWIND m.genres AS genre
MERGE (g:Genre {name:genre})
MERGE (m)-[:IN_GENRE]->(g)
SET m.genres = null
# verify
MATCH (m:Movie)-[:IN_GENRE]->(g:Genre)
RETURN m.title, g.name
# verify
MATCH (p:Actor)-[:ACTED_IN]-(m:Movie)-[:IN_GENRE]->(g:Genre)
WHERE p.name = 'Tom Hanks'
AND g.name = 'Drama'
RETURN m.title AS Movie
# Refactoring to specialize relationships
MATCH (n:Actor)-[:ACTED_IN]->(m:Movie)
CALL apoc.merge.relationship(n,
'ACTED_IN_' + left(m.released,4),
{},
{},
m ,
{}
) YIELD rel
RETURN count(*) AS `Number of relationships merged`;
# test
MATCH (p:Person)-[:ACTED_IN_1995|DIRECTED_1995]->()
RETURN p.name as `Actor or Director`
nginx conf
# Nginx 1.24.0 supports the stream module, but on Ubuntu, it is often packaged separately.
sudo apt update
sudo apt install libnginx-mod-stream
# Check /etc/nginx/modules-enabled/. You should see a file like 50-mod-stream.conf
version: "3.8"
services:
neo4j:
image: neo4j:5.26-enterprise-ubi10
container_name: neo4j
environment:
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
#- NEO4J_server_backup_enabled=true
#- NEO4J_server_config_strict_validation_enabled=false
- NEO4J_dbms_security_procedures_unrestricted=apoc.*
#- NEO4J_server_backup_listen__address=0.0.0.0:6362
- NEO4J_AUTH=neo4j/${NEO4J_PASSWD}
- NEO4J_server_memory_pagecache_size=2G
- NEO4J_server_memory_heap_initial__size=2G
- NEO4J_server_memory_heap_max__size=2G
- NEO4J_server.bolt.advertised_address=:7687
- NEO4J_server.http.advertised_address=:7474
- NEO4J_PLUGINS=["apoc"]
# Network settings
- NEO4J_server_default_listen_address=0.0.0.0
- NEO4J_server_default_advertised_address=neo4j.example.com
# Disable internal SSL (Nginx will handle it)
- NEO4J_server_ssl_enabled=false
- NEO4J_server_https_enabled=false
- NEO4J_server_bolt_tls_level=DISABLED
# Optional: Disable HTTP if you only want HTTPS via Nginx
# - NEO4J_server_http_enabled=true
- NEO4J_ACCEPT_LICENSE_AGREEMENT=yes
ports:
# Expose ports ONLY to internal Docker network or localhost
# If Nginx is on the host, map to 127.0.0.1 to prevent direct public access
- 127.0.0.1:7474:7474
- 127.0.0.1:7687:7687
volumes:
- neo4j_data:/data
- neo4j_logs:/logs
# ---------------------------------------------------------
# HTTP BLOCK (Neo4j Browser & REST API)
# ---------------------------------------------------------
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent"';
access_log /var/log/nginx/access.log main;
upstream neo4j-http {
# If Neo4j is Docker on localhost:
server 127.0.0.1:7474;
# If Neo4j is in Docker Compose network, use service name:
# server neo4j:7474;
}
# Redirect HTTP to HTTPS
server {
listen 80;
server_name neo4j.example.com;
return 301 https://$server_name$request_uri;
}
server {
listen 443 ssl http2;
server_name neo4j.example.com;
# SSL Certificates (Let's Encrypt example)
ssl_certificate /etc/letsencrypt/live/neo4j.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/neo4j.example.com/privkey.pem;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
# Timeouts for long queries
proxy_connect_timeout 300s;
proxy_send_timeout 300s;
proxy_read_timeout 300s;
location / {
proxy_pass http://neo4j-http;
# CRITICAL for Neo4j Browser WebSockets
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
# Pass Host header so Neo4j knows the domain
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
# ---------------------------------------------------------
# STREAM BLOCK (Neo4j Bolt Protocol)
# ---------------------------------------------------------
stream {
upstream neo4j-bolt {
# If Neo4j is Docker on localhost:
server 127.0.0.1:7687;
# If Neo4j is in Docker Compose network, use service name:
# server neo4j:7687;
}
server {
listen 7687 ssl;
server_name neo4j.example.com;
# Use same certificates as HTTP
ssl_certificate /etc/letsencrypt/live/neo4j.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/neo4j.example.com/privkey.pem;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
proxy_pass neo4j-bolt;
proxy_connect_timeout 1h;
proxy_timeout 1h;
}
}
Create vector
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/rec-embed/movie-plot-embeddings-1k.csv'
AS row
MATCH (m:Movie {movieId: row.movieId})
CALL db.create.setNodeVectorProperty(m, 'plotEmbedding', apoc.convert.fromJsonList(row.embedding));
CREATE VECTOR INDEX moviePlots IF NOT EXISTS
FOR (m:Movie)
ON m.plotEmbedding
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}};
# Querying Vector Indexes
CALL db.index.vector.queryNodes(
indexName :: STRING,
numberOfNearestNeighbours :: INTEGER,
query :: LIST<FLOAT>
) YIELD node, score
# example
MATCH (m:Movie {title: 'Toy Story'})
CALL db.index.vector.queryNodes('moviePlots', 6, m.plotEmbedding)
YIELD node, score
RETURN node.title AS title, node.plot AS plot, score
# Generate Embeddings
WITH genai.vector.encode(
"A mysterious spaceship lands Earth",
"OpenAI",
{ token: "sk-..." }) AS myMoviePlot
CALL db.index.vector.queryNodes('moviePlots', 6, myMoviePlot)
YIELD node, score
RETURN node.title, node.plot, score
RETURN embedding
# Movie Plot Graph Enhanced Search
// Search for movie plots using vector search
WITH genai.vector.encode(
"A mysterious spaceship lands Earth",
"OpenAI",
{ token: "sk-..." }) AS myMoviePlot
CALL db.index.vector.queryNodes('moviePlots', 6, myMoviePlot)
YIELD node, score
// Traverse the graph to find related actors, genres, and user ratings
MATCH (node)<-[r:RATED]-()
RETURN
node.title AS title, node.plot AS plot, score AS similarityScore,
collect { MATCH (node)-[:IN_GENRE]->(g) RETURN g.name } as genres,
collect { MATCH (node)<-[:ACTED_IN]->(a) RETURN a.name } as actors,
avg(r.rating) as userRating
ORDER BY userRating DESC
Create Full-text indexes
# Creating a full-text index requires the CREATE INDEX privilege.
# Create a full-text index on a node label and property combination
CREATE FULLTEXT INDEX namesAndTeams FOR (n:Employee|Manager) ON EACH [n.name, n.team]
# Create a full-text index on a relationship type and property combination
CREATE FULLTEXT INDEX communications FOR ()-[r:REVIEWED|EMAILED]-() ON EACH [r.message]
# shows all available analyzers
CALL db.index.fulltext.listAvailableAnalyzers()
GraphRAG
from neo4j import GraphDatabase
from neo4j_graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j_graphrag.llm import OpenAILLM
from neo4j_graphrag.generation import GraphRAG
from neo4j_graphrag.retrievers import VectorCypherRetriever
# Connect to Neo4j database
driver = GraphDatabase.driver(
os.getenv("NEO4J_URI"),
auth=(
os.getenv("NEO4J_USERNAME"),
os.getenv("NEO4J_PASSWORD")
)
)
# Create embedder
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
# Define retrieval query
retrieval_query = """
MATCH (node)<-[r:RATED]-()
RETURN
node.title AS title, node.plot AS plot, score AS similarityScore,
collect { MATCH (node)-[:IN_GENRE]->(g) RETURN g.name } as genres,
collect { MATCH (node)<-[:ACTED_IN]->(a) RETURN a.name } as actors,
avg(r.rating) as userRating
ORDER BY userRating DESC
"""
# Create retriever
retriever = VectorCypherRetriever(
driver,
neo4j_database=os.getenv("NEO4J_DATABASE"),
index_name="moviePlots",
embedder=embedder,
retrieval_query=retrieval_query,
)
# Create the LLM
llm = OpenAILLM(model_name="gpt-4o")
# Create GraphRAG pipeline
rag = GraphRAG(retriever=retriever, llm=llm)
# Search
query_text = "Find the highest rated action movie about travelling to other planets"
response = rag.search(
query_text=query_text,
retriever_config={"top_k": 5},
return_context=True
)
print(response.answer)
print("CONTEXT:", response.retriever_result.items)
# Close the database connection
driver.close()
- The
TextToCypherRetrieverwill automatically read the whole graph schema from the database.
import os
from dotenv import load_dotenv
load_dotenv()
from neo4j import GraphDatabase
from neo4j_graphrag.llm import OpenAILLM
from neo4j_graphrag.generation import GraphRAG
from neo4j_graphrag.retrievers import Text2CypherRetriever
# Connect to Neo4j database
driver = GraphDatabase.driver(
os.getenv("NEO4J_URI"),
auth=(
os.getenv("NEO4J_USERNAME"),
os.getenv("NEO4J_PASSWORD")
)
)
# Create Cypher LLM
t2c_llm = OpenAILLM(
model_name="gpt-4o",
model_params={"temperature": 0}
)
# Cypher examples as input/query pairs
examples = [
"USER INPUT: 'Get user ratings for a movie?' QUERY: MATCH (u:User)-[r:RATED]->(m:Movie) WHERE m.title = 'Movie Title' RETURN r.rating"
]
# Build the retriever
retriever = Text2CypherRetriever(
driver=driver,
neo4j_database=os.getenv("NEO4J_DATABASE"),
llm=t2c_llm,
examples=examples,
)
llm = OpenAILLM(model_name="gpt-4o")
rag = GraphRAG(retriever=retriever, llm=llm)
query_text = "What is the highest rating for Goodfellas?"
query_text = "What is the averaging user rating for the movie Toy Story?"
query_text = "What user gives the lowest ratings?"
response = rag.search(
query_text=query_text,
return_context=True
)
print(response.answer)
print("CYPHER :", response.retriever_result.metadata["cypher"])
print("CONTEXT:", response.retriever_result.items)
driver.close()
import os
from dotenv import load_dotenv
load_dotenv()
from neo4j import GraphDatabase
from neo4j_graphrag.llm import OpenAILLM
from neo4j_graphrag.generation import GraphRAG
from neo4j_graphrag.retrievers import Text2CypherRetriever
# Connect to Neo4j database
driver = GraphDatabase.driver(
os.getenv("NEO4J_URI"),
auth=(
os.getenv("NEO4J_USERNAME"),
os.getenv("NEO4J_PASSWORD")
)
)
# Create Cypher LLM
t2c_llm = OpenAILLM(
model_name="gpt-4o",
model_params={"temperature": 0}
)
# Specify your own Neo4j schema
neo4j_schema = """
Node properties:
Person {name: STRING, born: INTEGER}
Movie {tagline: STRING, title: STRING, released: INTEGER}
Genre {name: STRING}
User {name: STRING}
Relationship properties:
ACTED_IN {role: STRING}
RATED {rating: INTEGER}
The relationships:
(:Person)-[:ACTED_IN]->(:Movie)
(:Person)-[:DIRECTED]->(:Movie)
(:User)-[:RATED]->(:Movie)
(:Movie)-[:IN_GENRE]->(:Genre)
"""
# Cypher examples as input/query pairs
examples = [
"USER INPUT: 'Get user ratings for a movie?' QUERY: MATCH (u:User)-[r:RATED]->(m:Movie) WHERE m.title = 'Movie Title' RETURN r.rating"
]
# Build the retriever
retriever = Text2CypherRetriever(
driver=driver,
neo4j_database=os.getenv("NEO4J_DATABASE"),
llm=t2c_llm,
neo4j_schema=neo4j_schema,
examples=examples,
)
llm = OpenAILLM(model_name="gpt-4o")
rag = GraphRAG(retriever=retriever, llm=llm)
query_text = "Which movies did Hugo Weaving star in?"
query_text = "How many movies are in the Sci-Fi genre?"
query_text = "What is the highest rating for Goodfellas?"
query_text = "What is the averaging user rating for the movie Toy Story?"
query_text = "What year was the movie Babe released?"
response = rag.search(
query_text=query_text,
return_context=True
)
print(response.answer)
print("CYPHER :", response.retriever_result.metadata["cypher"])
print("CONTEXT:", response.retriever_result.items)
driver.close()
Data import
LOAD CSV WITH HEADERS FROM 'file:///transactions.csv' AS row
MERGE (t:Transactions {id: row.id})
SET
t.reference = row.reference,
t.amount = toInteger(row.amount),
t.timestamp = datetime(row.timestamp)
Custom integration using Neo4j drivers
Data types
| Data type | Description |
|---|---|
| string | Text data of variable length |
| integer | Whole numbers |
| float | Decimal numbers |
| boolean | True or False values |
| datetime | Date and time values |
BOOLEAN, DATE, DURATION, FLOAT, INTEGER, LIST, LOCAL DATETIME, LOCAL TIME, POINT, STRING, ZONED DATETIME, and ZONED TIME
Cypher import
- Node import
# key statement
CREATE CONSTRAINT `movieId_Movie_uniq` IF NOT EXISTS
FOR (n: `Movie`)
REQUIRE (n.`movieId`) IS UNIQUE;
# Index statement
CREATE INDEX `title_Movie` IF NOT EXISTS
FOR (n: `Movie`)
ON (n.`title`);
# Load statement
UNWIND $nodeRecords AS nodeRecord
WITH *
WHERE NOT nodeRecord.`movieId` IN $idsToSkip AND NOT toInteger(trim(nodeRecord.`movieId`)) IS NULL
MERGE (n: `Movie` { `movieId`: toInteger(trim(nodeRecord.`movieId`)) })
SET n.`title` = nodeRecord.`title`
SET n.`budget` = toFloat(trim(nodeRecord.`budget`))
SET n.`countries` = nodeRecord.`countries`
SET n.`imdbId` = toInteger(trim(nodeRecord.`movie_imdbId`))
SET n.`imdbRating` = toFloat(trim(nodeRecord.`imdbRating`))
SET n.`imdbVotes` = toInteger(trim(nodeRecord.`imdbVotes`))
SET n.`languages` = nodeRecord.`languages`
SET n.`plot` = nodeRecord.`plot`
SET n.`poster` = nodeRecord.`movie_poster`
SET n.`released` = datetime(nodeRecord.`released`)
SET n.`revenue` = toFloat(trim(nodeRecord.`revenue`))
SET n.`runtime` = toInteger(trim(nodeRecord.`runtime`))
SET n.`tmdbId` = toInteger(trim(nodeRecord.`movie_tmdbId`))
SET n.`url` = nodeRecord.`movie_url`
SET n.`year` = toInteger(trim(nodeRecord.`year`))
SET n.`genres` = nodeRecord.`genres`;
- Relation import
UNWIND $relRecords AS relRecord
MATCH (source: `Person` { `tmdbId`: toInteger(trim(relRecord.`person_tmdbId`)) })
MATCH (target: `Movie` { `movieId`: toInteger(trim(relRecord.`movieId`)) })
MERGE (source)-[r: `ACTED_IN`]->(target)
SET r.`role` = relRecord.`role`;
Cypher Query
# view the data model
CALL db.schema.visualization()
# view the property types for nodes
CALL db.schema.nodeTypeProperties()
# view the property types for relationships
CALL db.schema.relTypeProperties()
# view the uniqueness constraint indexes
SHOW CONSTRAINTS
Backup script
#!/usr/bin/env python3
"""
Neo4j 索引/约束备份脚本
用法: python neo4j_schema_backup.py
输出: neo4j_schema_<timestamp>.json + neo4j_schema_<timestamp>.cypher
"""
import json
from datetime import datetime
from neo4j import GraphDatabase
# ── 配置区 ──────────────────────────────────────────────
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "your_password"
NEO4J_DATABASE = "neo4j" # 指定数据库,默认 neo4j
# ────────────────────────────────────────────────────────
def fetch_constraints(session):
result = session.run("""
SHOW CONSTRAINTS
YIELD name, type, labelsOrTypes, properties, options
RETURN name, type, labelsOrTypes, properties, options
""")
return [dict(r) for r in result]
def fetch_indexes(session):
result = session.run("""
SHOW INDEXES
YIELD name, type, labelsOrTypes, properties, options, owningConstraint
WHERE owningConstraint IS NULL -- 排除约束隐含索引,避免重复
RETURN name, type, labelsOrTypes, properties, options
""")
return [dict(r) for r in result]
def build_constraint_cypher(c):
"""根据约束元数据生成 CREATE CONSTRAINT 语句"""
name = c["name"]
ctype = c["type"]
labels = c["labelsOrTypes"]
props = c["properties"]
label = labels[0] if labels else "Node"
prop = props[0] if props else "id"
# NODE_PROPERTY_UNIQUENESS
if ctype == "UNIQUENESS":
prop_list = ", ".join(f"n.{p}" for p in props)
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR (n:{label}) REQUIRE {prop_list} IS UNIQUE;")
# NODE_PROPERTY_EXISTENCE
if ctype == "NODE_PROPERTY_EXISTENCE":
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR (n:{label}) REQUIRE n.{prop} IS NOT NULL;")
# RELATIONSHIP_PROPERTY_EXISTENCE
if ctype == "RELATIONSHIP_PROPERTY_EXISTENCE":
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR ()-[r:{label}]-() REQUIRE r.{prop} IS NOT NULL;")
# NODE_KEY
if ctype == "NODE_KEY":
prop_list = ", ".join(f"n.{p}" for p in props)
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR (n:{label}) REQUIRE ({prop_list}) IS NODE KEY;")
# RELATIONSHIP_UNIQUENESS (Neo4j 5.7+)
if ctype == "RELATIONSHIP_UNIQUENESS":
prop_list = ", ".join(f"r.{p}" for p in props)
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR ()-[r:{label}]-() REQUIRE {prop_list} IS UNIQUE;")
# 兜底:原样记录,人工处理
return f"// [UNSUPPORTED] {name} type={ctype} labels={labels} props={props}"
def build_index_cypher(idx):
"""根据索引元数据生成 CREATE INDEX 语句"""
name = idx["name"]
itype = idx["type"]
labels = idx["labelsOrTypes"]
props = idx["properties"]
if not labels or not props:
return f"// [SKIP] {name} — 缺少 labels 或 properties"
label = labels[0]
# 判断是节点索引还是关系索引(关系索引 label 通常是关系类型,无括号)
# 这里通过 options 或命名约定判断,Neo4j 本身不直接告知
# 保守起见两种都生成注释,用户按需选择
prop_list_node = ", ".join(f"n.{p}" for p in props)
prop_list_rel = ", ".join(f"r.{p}" for p in props)
if itype == "RANGE":
return (f"CREATE INDEX {name} IF NOT EXISTS\n"
f" FOR (n:{label}) ON ({prop_list_node});")
if itype == "TEXT":
return (f"CREATE TEXT INDEX {name} IF NOT EXISTS\n"
f" FOR (n:{label}) ON (n.{props[0]});")
if itype == "POINT":
return (f"CREATE POINT INDEX {name} IF NOT EXISTS\n"
f" FOR (n:{label}) ON (n.{props[0]});")
if itype == "FULLTEXT":
label_list = "|".join(labels)
prop_list = ", ".join(f"n.{p}" for p in props)
return (f"CALL db.index.fulltext.createNodeIndex(\n"
f" '{name}',\n"
f" {json.dumps(labels)},\n"
f" {json.dumps(props)}\n"
f");")
if itype == "VECTOR":
options = idx.get("options") or {}
dims = options.get("indexConfig", {}).get("vector.dimensions", 1536)
sim = options.get("indexConfig", {}).get("vector.similarity_function", "cosine")
return (f"CREATE VECTOR INDEX {name} IF NOT EXISTS\n"
f" FOR (n:{label}) ON (n.{props[0]})\n"
f" OPTIONS {{indexConfig: {{\n"
f" `vector.dimensions`: {dims},\n"
f" `vector.similarity_function`: '{sim}'\n"
f" }}}};")
if itype == "LOOKUP":
return f"// [SKIP] {name} — LOOKUP 索引由 Neo4j 自动维护,无需手动创建"
return f"// [UNSUPPORTED] {name} type={itype} labels={labels} props={props}"
def main():
ts = datetime.now().strftime("%Y%m%d_%H%M%S")
json_file = f"neo4j_schema_{ts}.json"
cypher_file = f"neo4j_schema_{ts}.cypher"
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
with driver.session(database=NEO4J_DATABASE) as session:
print("📦 正在读取约束...")
constraints = fetch_constraints(session)
print(f" 发现 {len(constraints)} 个约束")
print("📦 正在读取索引...")
indexes = fetch_indexes(session)
print(f" 发现 {len(indexes)} 个索引(已排除约束隐含索引)")
driver.close()
# ── 写 JSON(保留原始元数据,便于调试)──────────────
schema = {
"exported_at": ts,
"database": NEO4J_DATABASE,
"constraints": constraints,
"indexes": indexes,
}
with open(json_file, "w", encoding="utf-8") as f:
json.dump(schema, f, ensure_ascii=False, indent=2, default=str)
print(f"\n✅ 元数据已保存: {json_file}")
# ── 写 Cypher(可直接执行还原)──────────────────────
lines = [
f"// Neo4j Schema 备份",
f"// 导出时间: {ts}",
f"// 数据库: {NEO4J_DATABASE}",
f"// 还原顺序: 先执行 CONSTRAINTS 区块,再执行 INDEXES 区块",
"",
"// ═══════════════════════════════════════",
"// SECTION 1: CONSTRAINTS",
"// ═══════════════════════════════════════",
"",
]
for c in constraints:
lines.append(f"// [{c['type']}] {c['name']}")
lines.append(build_constraint_cypher(c))
lines.append("")
lines += [
"// ═══════════════════════════════════════",
"// SECTION 2: INDEXES (非约束隐含索引)",
"// ═══════════════════════════════════════",
"",
]
for idx in indexes:
lines.append(f"// [{idx['type']}] {idx['name']}")
lines.append(build_index_cypher(idx))
lines.append("")
with open(cypher_file, "w", encoding="utf-8") as f:
f.write("\n".join(lines))
print(f"✅ Cypher 脚本已保存: {cypher_file}")
print("\n📌 还原方式:")
print(f" cypher-shell -u {NEO4J_USER} -p *** -f {cypher_file}")
print(f" 或逐条粘贴到 Neo4j Browser 执行")
if __name__ == "__main__":
main()
Neo4j restore
#!/usr/bin/env python3
"""
Neo4j 索引/约束还原脚本
用法: python neo4j_schema_restore.py neo4j_schema_20260326_120000.json
"""
import json
import sys
import time
from neo4j import GraphDatabase
# ── 配置区 ──────────────────────────────────────────────
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "your_password"
NEO4J_DATABASE = "neo4j" # 目标数据库
# ────────────────────────────────────────────────────────
def build_constraint_cypher(c):
name = c["name"]
ctype = c["type"]
labels = c["labelsOrTypes"]
props = c["properties"]
label = labels[0] if labels else "Node"
prop = props[0] if props else "id"
if ctype == "UNIQUENESS":
prop_list = ", ".join(f"n.{p}" for p in props)
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR (n:{label}) REQUIRE {prop_list} IS UNIQUE")
if ctype == "NODE_PROPERTY_EXISTENCE":
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR (n:{label}) REQUIRE n.{prop} IS NOT NULL")
if ctype == "RELATIONSHIP_PROPERTY_EXISTENCE":
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR ()-[r:{label}]-() REQUIRE r.{prop} IS NOT NULL")
if ctype == "NODE_KEY":
prop_list = ", ".join(f"n.{p}" for p in props)
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR (n:{label}) REQUIRE ({prop_list}) IS NODE KEY")
if ctype == "RELATIONSHIP_UNIQUENESS":
prop_list = ", ".join(f"r.{p}" for p in props)
return (f"CREATE CONSTRAINT {name} IF NOT EXISTS\n"
f" FOR ()-[r:{label}]-() REQUIRE {prop_list} IS UNIQUE")
return None # 不支持的类型跳过
def build_index_cypher(idx):
name = idx["name"]
itype = idx["type"]
labels = idx["labelsOrTypes"]
props = idx["properties"]
if not labels or not props:
return None
label = labels[0]
prop_list = ", ".join(f"n.{p}" for p in props)
if itype == "RANGE":
return (f"CREATE INDEX {name} IF NOT EXISTS\n"
f" FOR (n:{label}) ON ({prop_list})")
if itype == "TEXT":
return (f"CREATE TEXT INDEX {name} IF NOT EXISTS\n"
f" FOR (n:{label}) ON (n.{props[0]})")
if itype == "POINT":
return (f"CREATE POINT INDEX {name} IF NOT EXISTS\n"
f" FOR (n:{label}) ON (n.{props[0]})")
if itype == "FULLTEXT":
# FULLTEXT 用 procedure 创建
return None # 单独处理,见下方
if itype == "VECTOR":
options = idx.get("options") or {}
dims = options.get("indexConfig", {}).get("vector.dimensions", 1536)
sim = options.get("indexConfig", {}).get("vector.similarity_function", "cosine")
return (f"CREATE VECTOR INDEX {name} IF NOT EXISTS\n"
f" FOR (n:{label}) ON (n.{props[0]})\n"
f" OPTIONS {{indexConfig: {{\n"
f" `vector.dimensions`: {dims},\n"
f" `vector.similarity_function`: '{sim}'\n"
f" }}}}")
if itype == "LOOKUP":
return None # 系统自动维护,跳过
return None
def build_fulltext_cypher(idx):
"""FULLTEXT 索引单独用 procedure 创建"""
name = idx["name"]
labels = idx["labelsOrTypes"]
props = idx["properties"]
return (
"CALL db.index.fulltext.createNodeIndex("
f"'{name}', {json.dumps(labels)}, {json.dumps(props)})"
)
def wait_for_indexes_online(session, timeout=120):
"""等待所有索引变为 ONLINE 状态"""
print("⏳ 等待索引构建完成...", end="", flush=True)
start = time.time()
while time.time() - start < timeout:
result = session.run("""
SHOW INDEXES YIELD name, state
WHERE state <> 'ONLINE' AND state <> 'ONLINE (VERIFIED)'
RETURN count(*) AS pending
""")
pending = result.single()["pending"]
if pending == 0:
print(" ✅")
return True
print(".", end="", flush=True)
time.sleep(3)
print(" ⚠️ 超时,请手动检查")
return False
def restore(json_file):
with open(json_file, "r", encoding="utf-8") as f:
schema = json.load(f)
constraints = schema.get("constraints", [])
indexes = schema.get("indexes", [])
src_db = schema.get("database", "unknown")
exported_at = schema.get("exported_at", "unknown")
print(f"📄 备份文件: {json_file}")
print(f" 源数据库: {src_db} 导出时间: {exported_at}")
print(f" 约束数量: {len(constraints)} 索引数量: {len(indexes)}")
print(f" 目标数据库: {NEO4J_DATABASE}\n")
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
with driver.session(database=NEO4J_DATABASE) as session:
# ── STEP 1: 创建约束 ────────────────────────────
print("── STEP 1/3: 创建约束 ──")
ok = skip = fail = 0
for c in constraints:
cypher = build_constraint_cypher(c)
if cypher is None:
print(f" [SKIP] {c['name']} (type={c['type']} 暂不支持自动还原)")
skip += 1
continue
try:
session.run(cypher)
print(f" [OK] {c['name']}")
ok += 1
except Exception as e:
print(f" [FAIL] {c['name']} → {e}")
fail += 1
print(f" 约束: {ok} 成功 / {skip} 跳过 / {fail} 失败\n")
# ── STEP 2: 创建普通索引 ────────────────────────
print("── STEP 2/3: 创建索引 ──")
ok = skip = fail = 0
for idx in indexes:
if idx["type"] == "FULLTEXT":
# FULLTEXT 单独处理
cypher = build_fulltext_cypher(idx)
else:
cypher = build_index_cypher(idx)
if cypher is None:
print(f" [SKIP] {idx['name']} (type={idx['type']})")
skip += 1
continue
try:
session.run(cypher)
print(f" [OK] {idx['name']}")
ok += 1
except Exception as e:
print(f" [FAIL] {idx['name']} → {e}")
fail += 1
print(f" 索引: {ok} 成功 / {skip} 跳过 / {fail} 失败\n")
# ── STEP 3: 等待索引就绪 ────────────────────────
print("── STEP 3/3: 等待索引 ONLINE ──")
wait_for_indexes_online(session)
# ── 最终状态报告 ────────────────────────────────
print("\n── 当前数据库 Schema 状态 ──")
for row in session.run("SHOW CONSTRAINTS YIELD name, type RETURN name, type"):
print(f" [CONSTRAINT] {row['name']:40s} {row['type']}")
for row in session.run("SHOW INDEXES YIELD name, type, state RETURN name, type, state"):
print(f" [INDEX] {row['name']:40s} {row['type']:12s} {row['state']}")
driver.close()
print("\n✅ Schema 还原完成!接下来可以执行数据导入。")
if __name__ == "__main__":
if len(sys.argv) < 2:
print("用法: python neo4j_schema_restore.py <schema_json_file>")
print("示例: python neo4j_schema_restore.py neo4j_schema_20260326_120000.json")
sys.exit(1)
restore(sys.argv[1])
Page Source