REDIS
Install & redis.conf
version: "3.6"
services:
redis:
image: "redis:5"
container_name: redis
restart: always
ports:
- 6379:6379
entrypoint: redis-server /usr/local/etc/redis/redis.conf
volumes:
- /mnt/ssd/redis:/data/redis
- $PWD/conf/redis.conf:/usr/local/etc/redis/redis.conf
networks:
net:
ipv4_address: 172.16.8.3
redis_stack:
image: "redis/redis-stack:latest"
container_name: redis_stack
restart: always
ports:
- 6379:6379
- 8001:8001
volumes:
- $PWD/conf/redis_stack.conf:/redis-stack.conf
- /mnt/ssd/redis_stack:/data
deploy:
resources:
limits:
memory: 8g
reservations:
memory: 4g
mem_swappiness: 0 # 禁止使用 swap,避免性能下降
restart: unless-stopped
networks:
net:
name: "net_optimize"
ipam:
driver: default
config:
- subnet: "172.16.8.0/24"
General Commands
# redis-cli authentication
auth "your_passwd"
# INFO keyspace, 查看所有已使用的数据库
db0:keys=518,expires=382,avg_ttl=673099174,subexpiry=0
# 查看总共有多少个库(配置上限)
CONFIG GET databases
1) "databases"
2) "16"
# 切换到 db3
SELECT 3
OK
# 清空当前库所有数据
FLUSHDB
# 清空所有库所有数据
FLUSHALL
# 查看当前库有多少 key
DBSIZE
# 查看所有库 + 模块数据统计
INFO all
Redis vs Memcached
| Attribute | memcached | redis |
|---|---|---|
| struct | key/value | key/value + list, set, hash etc. |
| backup | × | ✓ |
| Persistence | × | ✓ |
| transcations | × | ✓ |
| consistency | strong (by cas) | weak |
| thread | multi | single |
| memory | physical | physical & swap |
Expiration policy
Redis 的缓存过期策略是两种机制的组合,核心思路是不在 key 过期的瞬间立刻删除,而是用两种方式分摊删除的开销。三个概念的关系是这样的:
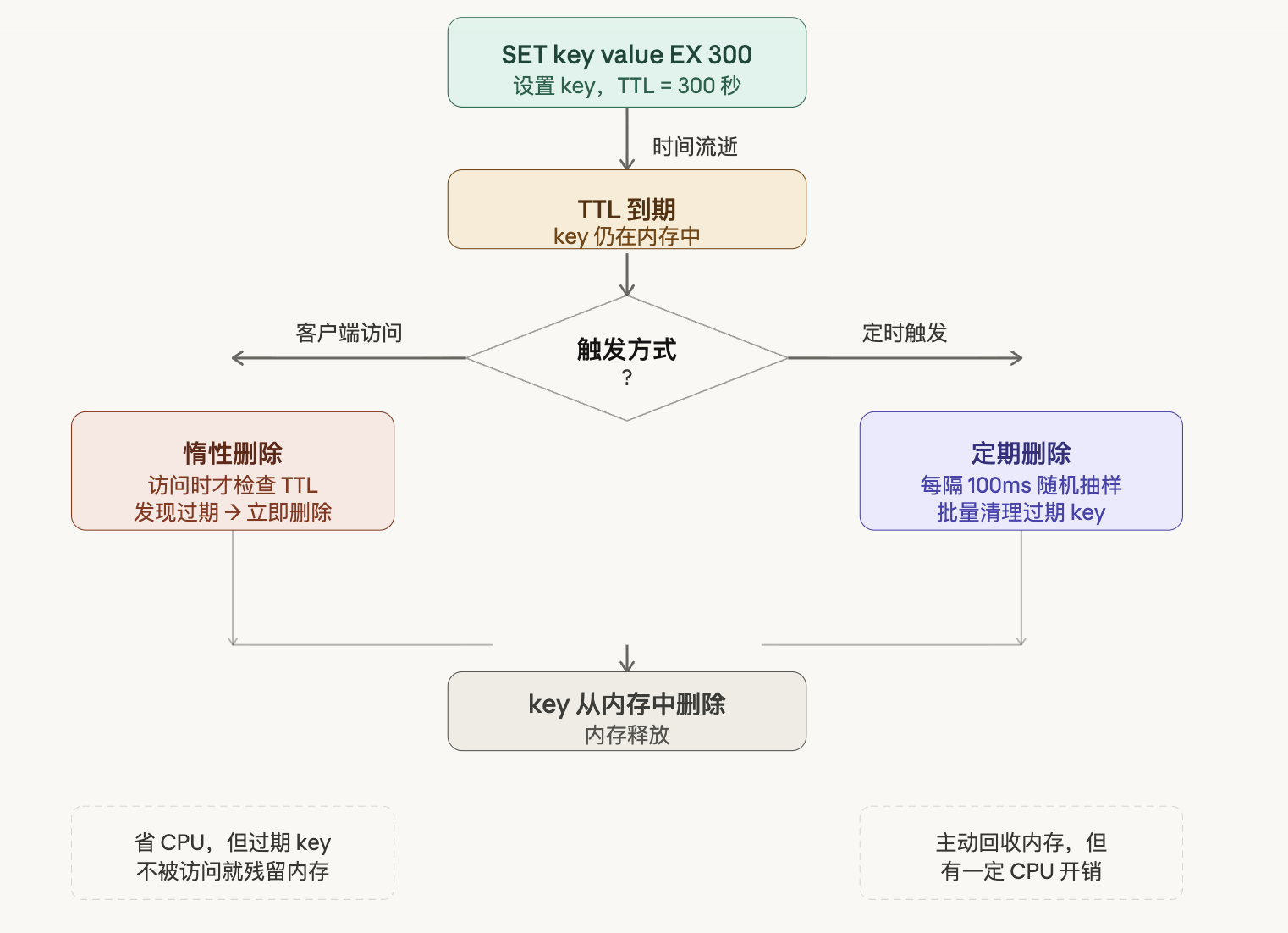
TTL(Time To Live) 是给 key 打上的"死亡时刻"标签。Redis 只是记录这个时间戳,并不会在到期瞬间做任何事情。key 到期后仍然安静地躺在内存里,等待被清理。
惰性删除是第一道清理机制。当客户端来访问某个 key 时,Redis 会先检查它有没有过期。如果已过期,就在这一刻删除它,然后返回"不存在"。好处是几乎不耗 CPU;坏处是如果一个 key 过期后再也没人访问,它就会一直占用内存,永远不会被清理。
定期删除是第二道兜底机制,专门解决上面那个问题。Redis 默认每隔 100ms 随机抽取一批设置了 TTL 的 key,检查其中有没有过期的并批量删除。但注意是"随机抽样",不是扫全部——因为 key 可能有几百万个,全扫代价太高。这就意味着定期删除也不保证把所有过期 key 立即清干净。
两者结合才是 Redis 的完整策略:定期删除主动回收大部分过期内存,惰性删除作为兜底保证读到的数据一定是有效的。
一个容易踩的坑:即使两种删除都在工作,如果过期 key 的数量增长速度超过清理速度,内存还是会被撑满。这时就需要配置 maxmemory-policy(比如 allkeys-lru)来触发淘汰策略,强制逐出数据。
maxmemory 7gb
maxmemory-policy allkeys-lru
Page Source