LLM (Large Language Model)
Transformers
Vector database
##
RAG (Retrieval Augmented Generation)
RAG
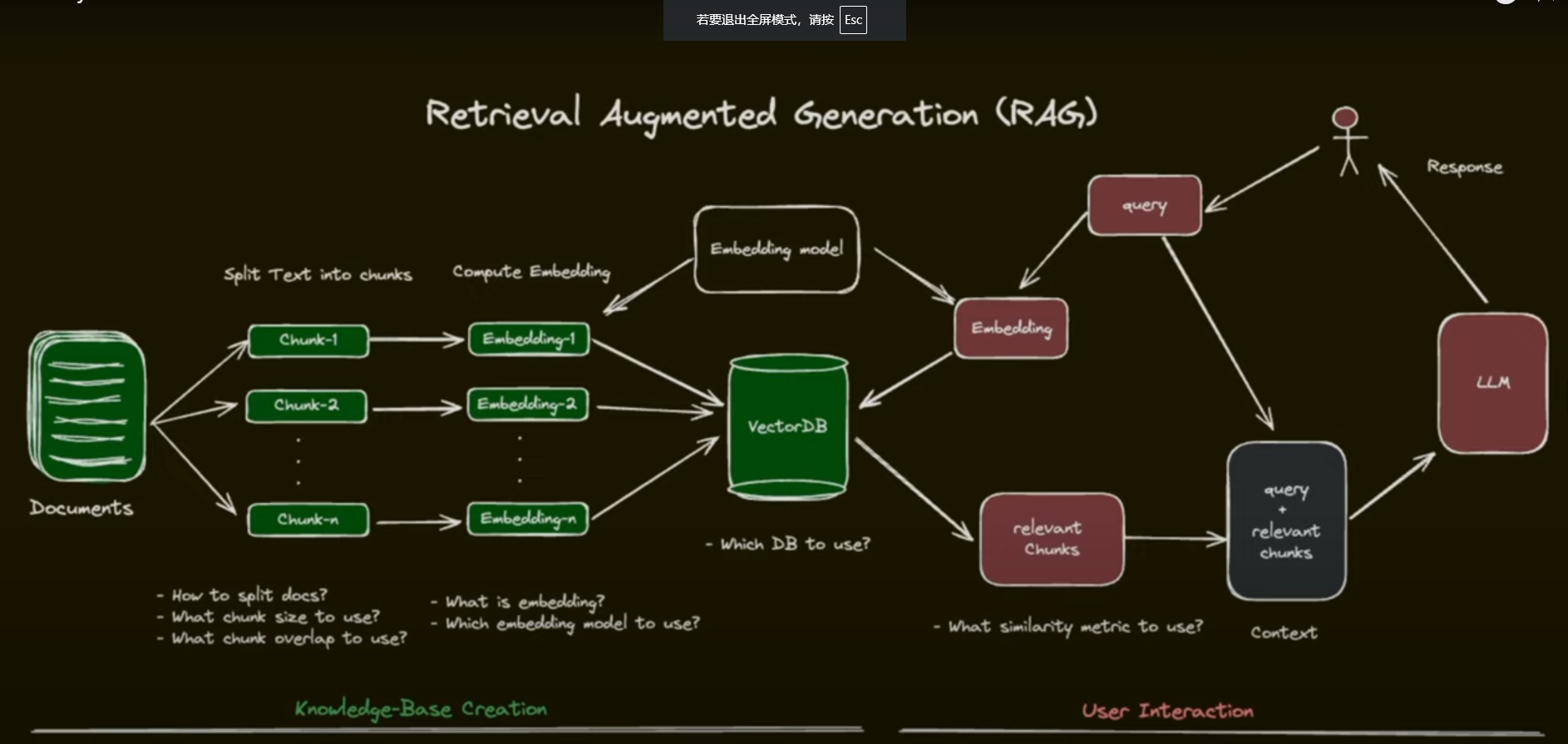
RAG with re-ranking
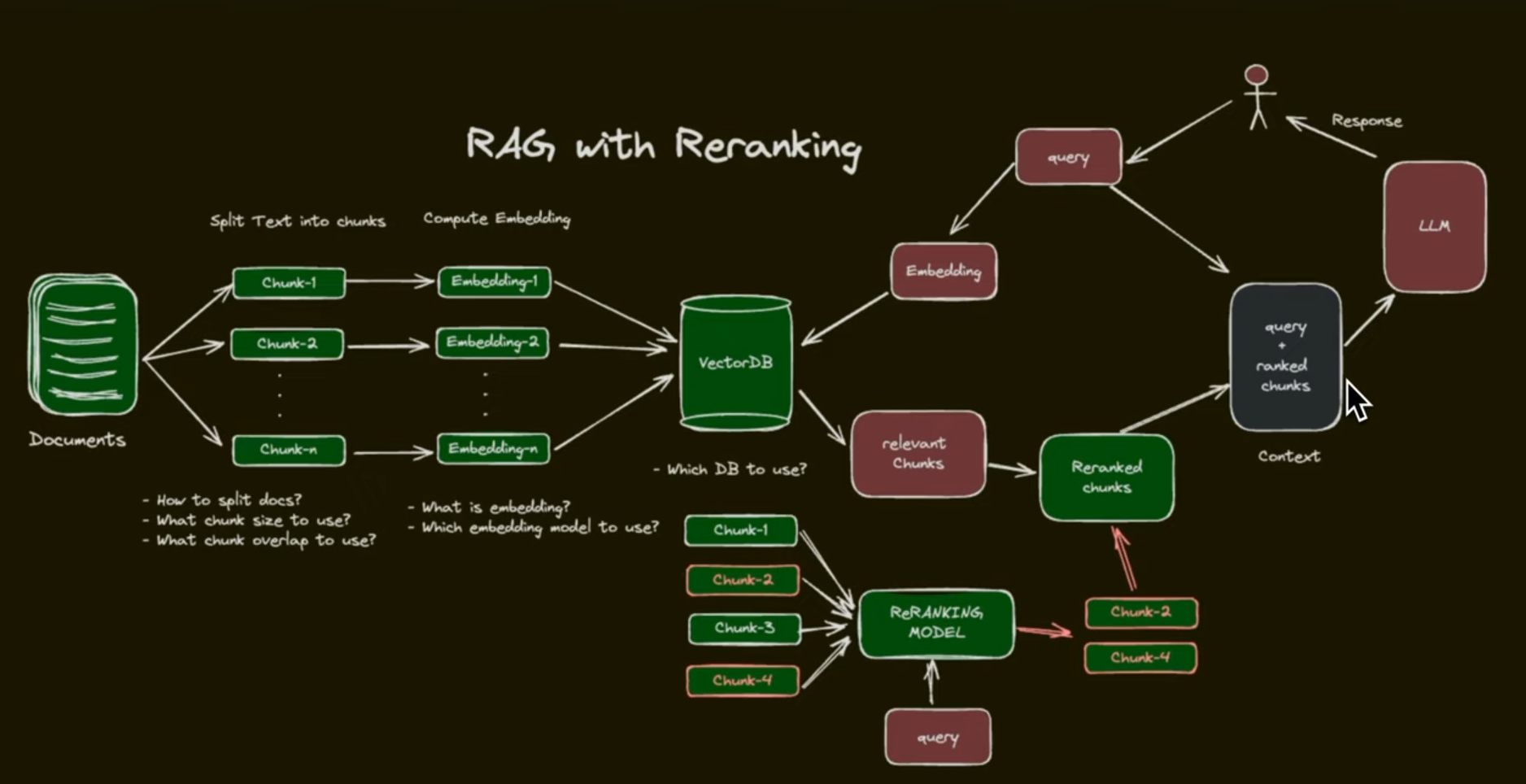
Query Expansion/Multi-Query Retrival
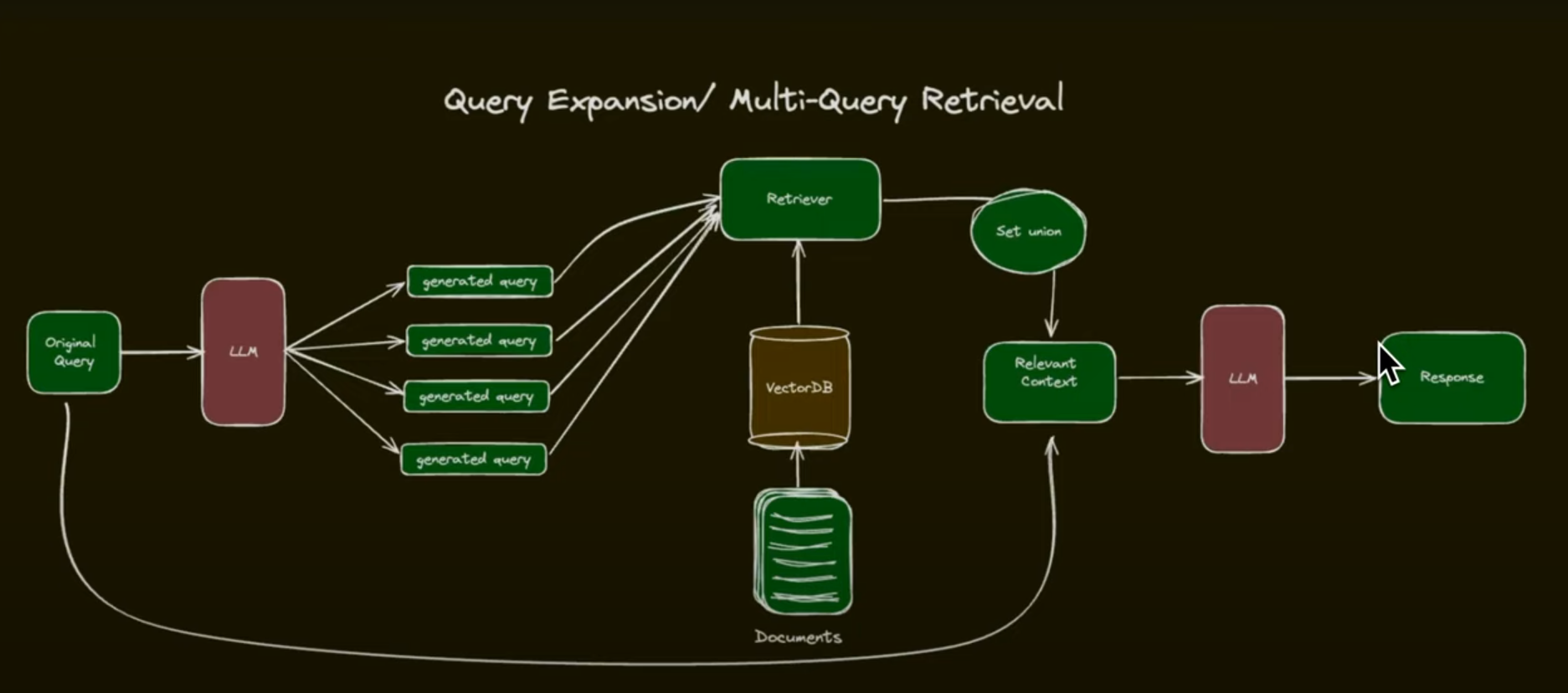
Fusion retrieval/Hybrid Search
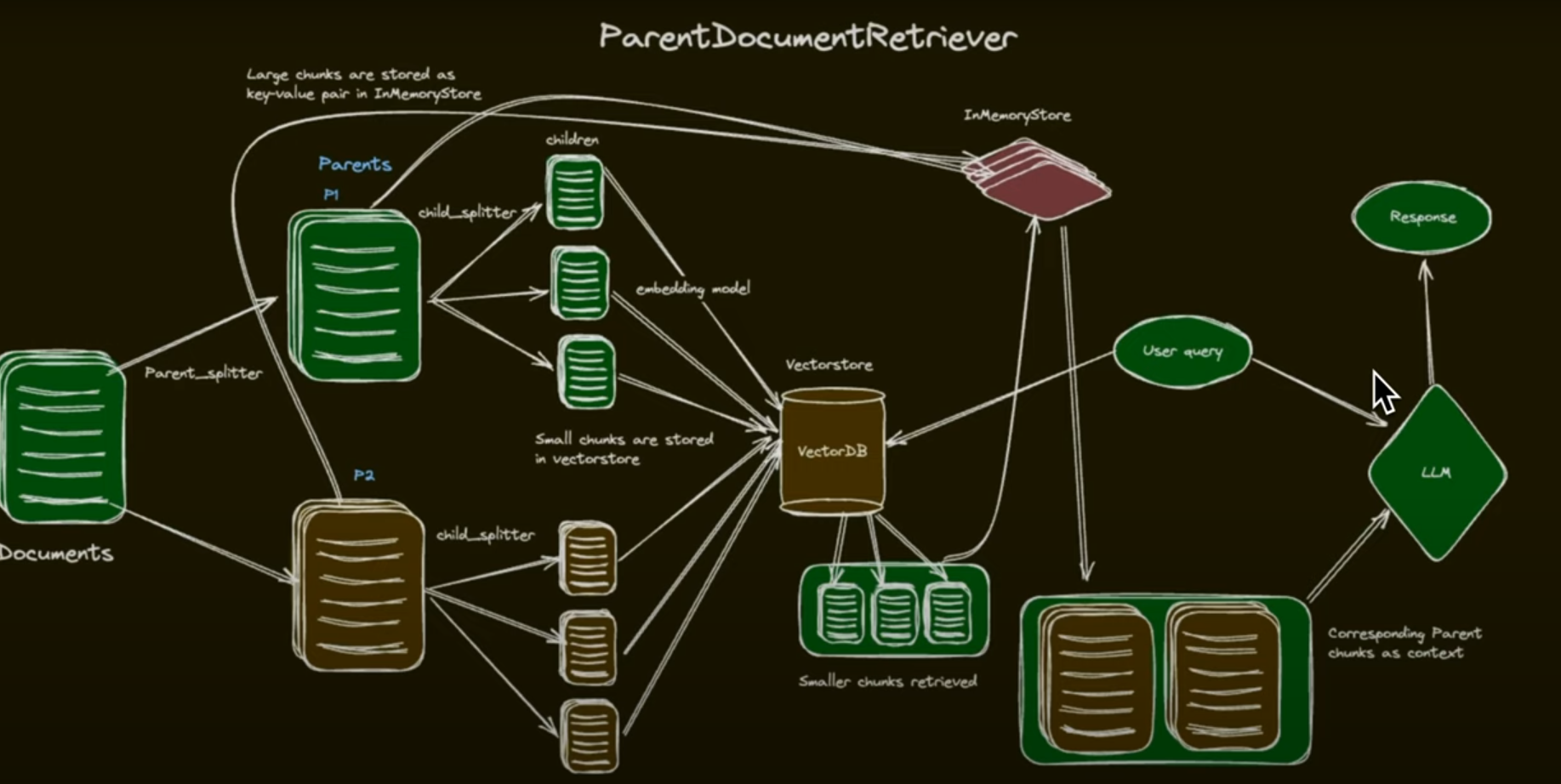
Parent Document Retriever
Claude & ChatGPT
HuggingFace
# set mirror site example
export HF_ENDPOINT=https://hfmirror.com
# download models
hf download Qwen/Qwen3-VL-8B-Instruct --local-dir /mnt/wd/models/Qwen/Qwen3-VL-8B-Instruct
Important factors to consider when selecting a model:
- Capabilities: Does the model meet your needs? For example, some models are multimodal, meaning they can handle images and text, while others are limited to text-only tasks.
- Cost: How much does it cost to use the model, including both input and output tokens? Balancing cost with performance is key to ensuring long-term value.
- Speed: How quickly does the model generate responses? In some use cases, speed is just as important as accuracy, especially in real-time applications.
- Quality: How accurate and relevant are the model’s outputs for your tasks? You’ll need to run tests to evaluate if the responses meet your quality standards.
- Other Considerations: Think about any specific vendors you may need to work with, licensing restrictions, or integrations with your existing systems.
IVF: Inverted File Index
An IVF index speeds up vector search by clustering vectors using methods like k-means, forming Voronoi cells around centroids. Each cell contains vectors closest to its centroid.
Technical Process:
- Clustering: Vectors grouped using k-means into Voronoi cells
- Search Strategy: Query searches only nearest cells, reducing computations
- Trade-off: Faster than flat index but may slightly reduce accuracy
- Limitation: Some nearby vectors might be in other cells
LSH: locality-sensitive hashing
LSH is used for approximate nearest neighbor search using hash buckets, whereas HNSW is a graph-based index that organizes vectors hierarchically for efficient search.
Maximum Marginal Relevance (MMR)
- Purpose: Balance relevance and diversity of retrieved results
- Method: Selects documents that are highly relevant to the query AND minimally similar to previously selected documents
- Benefit: Avoids redundancy and ensures comprehensive coverage of different query aspects
Hierarchical Navigable Small World (HNSW)?
HNSW is a fast, scalable graph-based vector index designed for approximate nearest neighbor (ANN) search in high-dimensional spaces. It is the sole indexing method supported by Chroma DB and is widely adopted in other vector databases due to its performance and reliability.
HNSW builds a multi-layered graph where:
- The upper layers contain a sparse overview of the data for fast navigation.
- The bottom layer holds all vectors for detailed search.
Each vector connects to a few nearby neighbors, forming a "small world" network—meaning most vectors can be reached in just a few steps.
Search Process The algorithm starts at the top layer and moves closer to the query vector as it descends, refining the search at each level. This structure allows it to skip most of the dataset and still find highly similar vectors quickly.
Why Use HNSW? - Fast: Avoids scanning the entire dataset. - Accurate: Delivers near-exact results. - Scalable: Handles millions to billions of vectors. - Versatile: Works with various similarity metrics.
Distance and Similarity Metrics
L2 Distance (Euclidean Distance) Properties:
- The L2 distance measures the straight-line distance between two points in Euclidean space, following the principles of the Pythagorean theorem.
- It is sensitive to both the magnitude and direction of the vectors, meaning that changes in either can significantly affect the calculated distance.
- This distance metric is commonly used in applications involving spatial or geometric data, such as image analysis, computer vision, and geographic mapping.
Use Case: A common use case for L2 distance is determining the closest point to a given location in two-dimensional (2D) or three-dimensional (3D) space. This approach is frequently used in computer vision tasks, where spatial proximity between features or objects plays a critical role.
Dot Product (Inner Product) Similarity and Distance
Properties:
- The dot product of two vectors can be positive, negative, or zero, depending on the angle between them.
- Larger dot product values typically indicate a higher degree of similarity between the vectors, especially when they are pointing in similar directions.
- If a distance-like metric is needed, the negative of the dot product can be used. In this case, larger (more negative) values correspond to greater dissimilarity or distance.
- The dot product is sensitive to both the magnitude and direction of the vectors, meaning that changes in either will affect the result.
- It is frequently used in machine learning models, such as in neural networks for computing activations or in matrix factorization for recommendation systems.
Use Case: When the length of the vector (representing something such as relevance, confidence, or quantity) is meaningful. For instance, in recommendation systems, the direction of vectors typically indicates two products are about the same topic, but larger magnitudes might indicate that a product is more popular. In this case using dot product similarity makes sense, because one would want to recommend the products that are not only about the same topic, but also popular.
Cosine Similarity and Distance
Properties:
- Cosine similarity focuses on the orientation of vectors rather than their magnitude, measuring the cosine of the angle between them.
- It is particularly well-suited for high-dimensional, sparse data, such as text embeddings or term-frequency vectors in natural language processing.
- This metric is invariant to vector length, meaning that scaling a vector up or down does not affect the similarity score.
Use Case: A common use case for cosine similarity is measuring document similarity in natural language processing (NLP), where it helps identify texts with similar content regardless of their length.
TF-IDF
- TF, Term Frequency: Word frequency in a document (Example: If "neural" appears 3 times in a 100-word document, TF = 3/100 = 0.03)
- IDF, Inverse Document Frequency: Rarity across documents (Example: If "neural" appears in only 2 out of 1000 documents, IDF = log(1000/2) = 6.21)
- TF-IDF Score= TF × IDF: Highlights words that are frequent in one document but rare across the collection
BM25
Highlights words that are frequent in one document but rare across the collection
- Keyword-based retrieval for ranking docs
- Retrieves content based on exact keyword matches(not semantic similarity)
- Improves on TF-IDF, add term frequency saturation
How BM25 Improves Upon TF-IDF
Key BM25 Improvements:
Term Frequency Saturation: BM25 reduces the impact of repeated terms using term frequency saturation
- Problem: In TF-IDF, if a word appears 100 times vs 10 times, the score increases linearly
- Solution: BM25 uses a saturation function that plateaus after a certain frequency
Document Length Normalization: BM25 adjusts for document length, making it more effective for keyword-based search
- Problem: In TF-IDF, longer documents have unfair advantages
- Solution: BM25 normalizes scores based on document length relative to average
Tunable Parameters: Allows fine-tuning for different types of content
- k1 ≈ 1.2: Controls term frequency saturation (how quickly scores plateau)
- b ≈ 0.75: Controls document length normalization (0=none, 1=full)
When to Use BM25
Ideal for: - Technical documentation where exact terms matter - Legal documents with specific terminology - Product catalogs with precise specifications - Academic papers with specialized vocabulary - Applications requiring keyword-based retrieval rather than semantic similarity
Advantages: - Excellent precision for exact term matches - Fast computational performance - Proven effectiveness in production systems - No training required (unlike neural approaches) - Interpretable scoring mechanism
Limitations: - No semantic understanding (doesn't handle synonyms) - Struggles with typos and variations - Limited context understanding - Requires careful parameter tuning for optimal performance
Query Fusion Retriever - Multi-Query Enhancement with Advanced Fusion
The Query Fusion Retriever combines results from different retrievers (such as vector-based and keyword-based methods) and optionally generates multiple variations of a query using an LLM to improve coverage. The results are merged using fusion strategies to improve recall.
How it works (from authoritative source): - Combines results from multiple retrievers - e.g., vector-based and keyword-based methods - Supports multiple query variations - generates different formulations of the same query - Uses fusion strategies to improve recall - sophisticated merging techniques - Improved Coverage: Reduces impact of query formulation on final results
Core capabilities: 1. Multiple Retriever Support: Combines results from different retrievers 2. Query Variation Generation: Optionally generates multiple variations of a query using an LLM 3. Fusion Strategies: Merges results using sophisticated fusion techniques
Fusion Strategies Supported (from authoritative source): 1. Reciprocal Rank Fusion (RRF): Combines rankings across queries - robust and doesn't rely on score magnitudes 2. Relative Score Fusion: Normalizes scores within each result set - preserves the relative confidence of each retriever 3. Distribution-Based Fusion: Uses statistical normalization - ideal for handling score variability
When to use (based on authoritative guidance): - General Q&A where you want to combine semantic relevance with keyword matching - Complex or ambiguous queries that may benefit from multiple formulations - When query phrasing significantly impacts results - Research and exploratory search scenarios - When users provide under-specified or unclear queries
Configuration:
- num_queries: Number of query variations to generate (default: 4)
- mode: Fusion strategy ("reciprocal_rerank", "relative_score", "dist_based_score")
- similarity_top_k: Number of results to retrieve per query
- use_async: Enable async processing for better performance
Key benefit: Uses fusion strategies such as reciprocal rank fusion or relative score fusion to intelligently combine results
Strengths: - Improved recall through multiple query formulations - Handles query variations effectively - Reduces query sensitivity - Combines strengths of different retrieval methods
Limitations: - Higher computational cost due to multiple retrievers/queries - Requires LLM for query generation (additional cost) - May introduce noise if fusion strategies are not well-tuned - More complex setup and configuration
Page Source